|
Heslop-Harrison Group Homepage Science Bovid (cow) diversity People Methods/techniques In situ Hybridization Molecular methods- lab protocols Technology development Courses and Science Pictures Journal editing Policy Information/Publications Jack Heslop-Harrison Links Site information
|
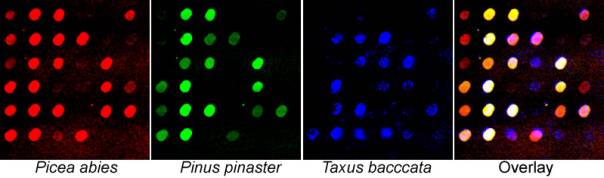
Microarrays and BiodiversityThis page currently tests youTube embedding. We do not have our own video content yet ... but will soon! We are using microarray hybridization to quantify the relative abundance of different repetitive elements. Below, a preliminary experiments is shown using three-colour microarray (100 μm spot size) hybridization with 36 retroelements as the target DNA placed on the microscope slide (Schleicher & Schuell, FAST slide), probed with genomic DNA from gymnosperms labelled with different colours of fluorochrome as the probe (read on a Perkin-Elmer - Packard - GSI Lumonics Scanarray 3000). Of the retroelements shown, some (left column, top three) are essentially specific to Picea, while others are essentially absent in the Pinaceae species (third and fourth row, fourth column). Other elements show differential abundances in the three species
are widely regarded to be low between species in Pinus or Picea (see, e.g., Kamm, Heslop-Harrison et al. 1996), but within and between species differences are greater and likely to be detected in Beta (see Kubis, Heslop-Harrison et al. 1997). Repetitive DNA in diversity analysis Repetitive DNA sequences make up 50-90% of the genome of most higher plant species (see Heslop-Harrison 2000; Kubis et al. 1998), and are rapidly evolving: individual motifs show changes in both copy number and sequence between closely related species. In contrast, genes are similar even over large taxonomic distances, evidenced by the fact that they can often be found in different species by amplification with conserved primers for PCR. We posit that it is of considerable importance to study repetitive DNA in the context of genomic diversity and plant evolution because of the sheer amount, its rapid evolution and the demonstrated effect on gene duplication and regulation of expression – key contributors to biodiversity. Repetitive DNA elements consist of sequence motifs ranging in size from dinucleotides to motifs of more than 10000 bp, and each motif is repeated from several hundreds, to hundreds of thousands, of times in the genome. Families of repetitive DNA sequences are differentiated by their degree of sequence homology, distribution among species, and their genomic and physical organization. Some sequence motifs are organized as tandem repeating units, where individual copies are arranged adjacent to each other forming tandem arrays of the monomeric unit. The arrays (clusters) are localized at one or more chromosomal sites, which may be pericentromeric, subtelomeric or intercalary. DNA elements arranged in tandem arrays include different types of satellite DNAs (often multiples of about 180 bp long, corresponding to DNA wrapped once around the nucleosomes core; Vershinin & Heslop-Harrison 1999), the telomeric repeat and the highly conserved rDNA genes. Other repetitive DNA sequences comprise elements with a dispersed chromosomal organization and variable sizes. Dispersed DNA sequences, which are interspersed with other sequences and distributed along the chromosomes (Brandes, Kubis, Heslop-Harrison et al. 1997), include mobile elements such as DNA transposable elements and retroelements. There are few examples where homologous sequences have been sequenced from different members of a group of related species, and this will be carried out here to characterize conserved and variable regions of repeats with respect to their evolution and diversity generation (see Contento pages and publications on this website, and also Tsujimoto and colleagues with AfaI sequence in Japan, both from cereals).. Sequences isolated by Nicolai Friesen (see conifer project and publication list)
|